
Mit COVID-19 Patientendaten zu trainieren machine-learning-Modelle für das Gesundheitswesen
Eine kurze Woche, ich rief die Regierungen auf, die Nutzung vorhandener Daten und bewährte maschinelles lernen und KI-Techniken zu helfen, Gesundheitssysteme, Bekämpfung der COVID-19-Pandemie.
Die Resonanz war erstaunlich. Mein team und ich erhielt Ermutigung, Ideen und Vorschläge für die Zusammenarbeit.
Auch wurden wir, mit freundlicher Genehmigung von Public Health England, eine Reihe von (anonymisierter) Daten, die auf bestehenden COVID-19 Fällen. Zusammen mit meinem team an der Cambridge Zentrum für AI in der Medizin, ich habe in den letzten Tagen die Ausbildung unserer Modelle auf diese Daten. Die Ergebnisse sind bisher sehr ermutigend.
Unter anderem wollten wir zeigen, dass machine learning-Techniken können genau Vorhersagen, wie COVID-19 wird Auswirkungen Ressourcenbedarf (Ventilatoren, ICU-Betten, etc.) auf der individuellen patientenebene und der Krankenhaus-Ebene, wodurch ein verlässliches Bild der zukünftigen Ressourcennutzung und ermöglichen healthcare-Profis, um fundierte Entscheidungen darüber, wie diese knappen Ressourcen können verwendet werden, um die Erreichung der maximalen nutzen.
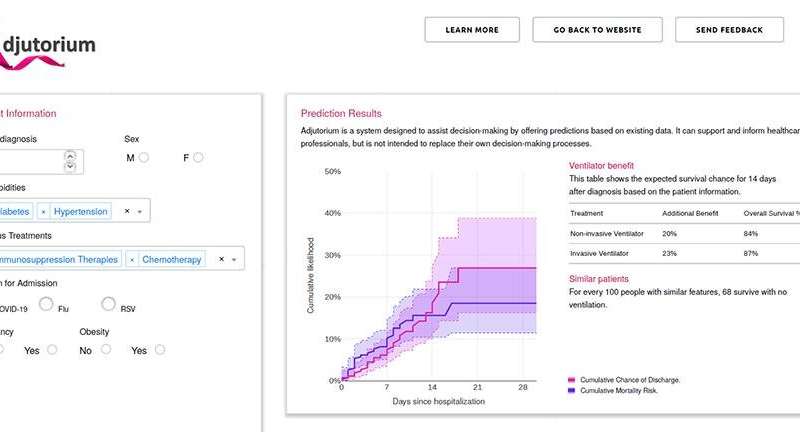
Basierend auf den Daten, die wir von der Öffentlichen Gesundheit England, wir haben nun einen proof-of-concept-demonstrator zeigt, dass dies getan werden kann, in form von einem neuen system, wir nennen Adjutorium.
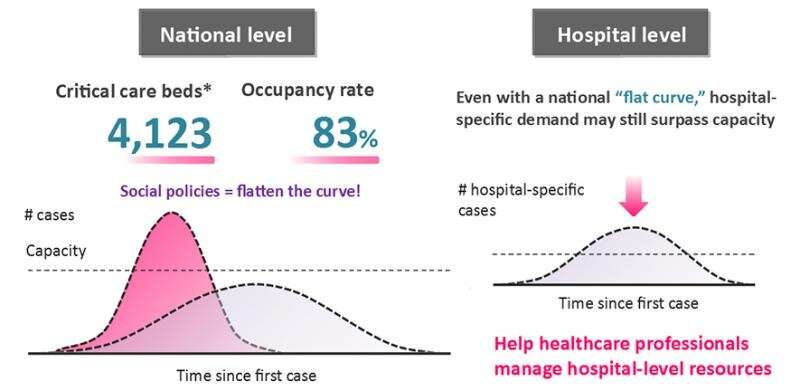
Ist das nicht die Abflachung der Kurve genug?
Sozialpolitik kann sicherlich helfen, zur Entlastung der Gesundheitssysteme auf der ganzen Welt. Aber es gibt keine Garantie, dass bestimmte einzelne Krankenhäuser nicht noch gestreckt werden, auch außerhalb der Kapazität. Darüber hinaus werden diese Maßnahmen möglicherweise nicht richtig beobachtet von allen, oder vielleicht entspannt sich langsam über die Zeit. Es ist wichtig zu gewährleisten, dass die Krankenhäuser bleiben bewaffnet mit Informationen, die Ihnen helfen, verwalten Spitzen in der Nachfrage nach Ressourcen, wie ICU-Betten oder Ventilatoren.
Als ich Sie berührte, nach der letzten Woche, Leben-oder-Tod-Entscheidungen werden gemacht in Bezug auf die Nutzung knapper Ressourcen wie Ventilatoren und Intensivbetten. Wenn Sie die Verwaltung oder in einem Krankenhaus arbeiten, wäre es unglaublich hilfreich (aber es ist derzeit nicht möglich), um eine hoch zuverlässige Bild der wahrscheinlichen Benutzung dieser Ressourcen über die Zeit.
Dies ist, was zu vielen medizinischen Fachkräften in aller Welt sind derzeit Gedanken über:
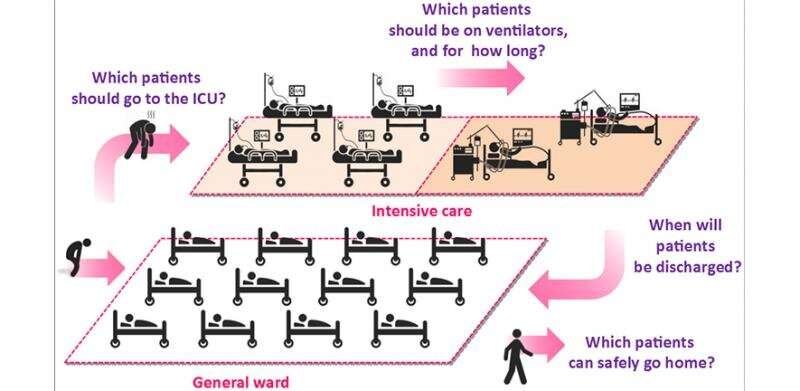
Wir können helfen, Antworten auf diese Fragen wird smart darüber, wie wir die bestehenden Daten über Krankenhauseinweisungen, ICU Eintritte, Nutzung von Ventilatoren, Patienten-outcomes (z.B. Entlassung, Sterblichkeit), und mehr. Wenn wir Zugriff auf qualitativ hochwertige Datensätze mit diesen Informationen können wir maschinelles lernen, um Fragen zu beantworten wie:
- Welche Patienten sind höchstwahrscheinlich brauchen Ventilatoren innerhalb einer Woche?
- Wie viele Kostenlose ICU-Betten ist das Krankenhaus voraussichtlich in einer Woche?
- Welche dieser beiden Patienten erhalten den größten nutzen aus gehen an ein Beatmungsgerät heute?
Während diese Fragen zuverlässig beantwortet werden mit Hilfe der machine learning-Techniken, die wir entwickelt haben, ich kann nicht genug betonen, dass die Entscheidungen selbst werden natürlich noch gemacht werden, die von Angehörigen der Gesundheitsberufe auf der Grundlage Ihrer organisation, der Prioritäten und Politiken.
Hier ist, wie ein machine-learning-Modell kann helfen, Fragen zu beantworten in einer Weise, die nützlich für Gesundheitsberufe:
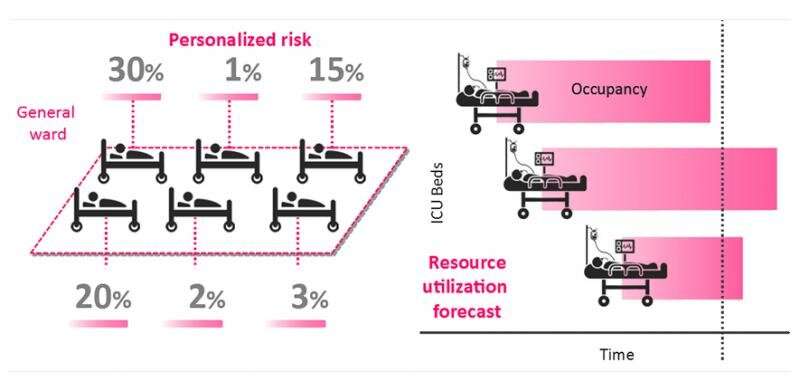
Wie Sie sehen können, den Patienten Risiko-scores, basierend auf die Wahrscheinlichkeit der Aufnahme in die intensivpflegestation oder ventilator-Nutzung. Diese werden dann aggregiert über die Klinik zu geben, sich ein Bild von zukünftigen Bedarf an Ressourcen.
Mit Public Health England Daten
Letzte Woche teilte ich der festen überzeugung, dass die bestehenden und bewährten machine-learning-Techniken können bereits bewältigen diese Art von Herausforderungen und liefert wesentliche Erkenntnisse, auch über vorhandene (evtl. ziemlich laut) Datenquellen. Dank der Daten, die wir von der Öffentlichen Gesundheit in England, ich fühle mich sicherer als je zuvor.
Wir empfangen Daten, die für nahezu 1.700 Patienten, und diese Zahl steigt weiter an, da der Datenbestand wird täglich aktualisiert. Während die Daten war unpersönlich, es enthält die grundlegenden Informationen, Laborwerte, Krankenhausaufenthalt details, Risikofaktoren und Ergebnisse.
Wir fütterten diese Daten zu AutoPrognosis, eine state-of-the-art automatisierten machine learning framework, dass unser team entwickelte im Jahr 2018 (zunächst für Herz-Kreislauf-Probleme, später aber auch für die zystische Fibrose und Brustkrebs, unter anderem).
Zur Vorhersage der Mortalität, verwendeten wir die Daten von 850 Patienten zu trainieren, unser Modell, und dann überprüft die Genauigkeit des Modells anhand der Ergebnisse aus 197 anderen Patienten aus dem gleichen dataset an. Für die Aufnahme in die intensivpflegestation Vorhersage, trainierten wir mit den Daten von 950 Patienten und überprüft die Daten von 285 Patienten. Vorhersagen müssen für die Belüftung, trainierten wir mit 810 Patienten und überprüft mit 276 Patienten.
Wir nannten das neue system, das wir geschaffen „Adjutorium“ und bedeutet Hilfe, Beistand oder Unterstützung.
Was wir gelernt haben
Also, wie hat Adjutorium durchführen? Einfach ausgedrückt: es Tat wirklich, wirklich gut.
Einmal trainiert mit Patienten-Daten, Adjutorium war in der Lage, sehr genaue Vorhersagen über die Patienten, deren Daten wir verwendet für die Prüfung. Entscheidend ist, dass wir es geschafft, so viel genauer als die bestehenden und weit verbreiteten survival-Analyse-Techniken wie Cox-regression oder bekannten Indizes, wie dem Charlson comorbidity index.
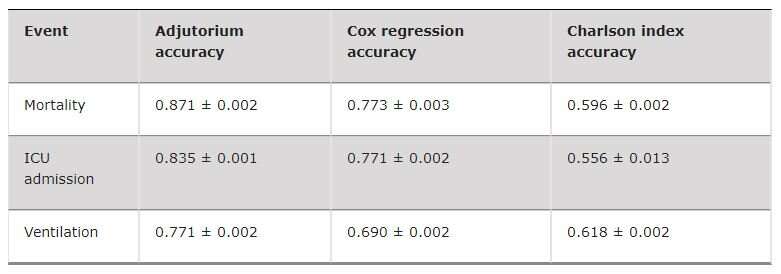
Es ist auch zu Bedenken, dass Adjutorium erzielt werden diese Ergebnisse mit einem relativ geringen Anteil der Daten, die gesammelt werden können von COVID-19 Fällen weltweit. Je mehr Daten wir Zugriff haben, desto besser können wir trainieren, unsere Modelle und verbessern die Genauigkeit, und desto nützlicher Adjutorium wird.
Die nächsten Schritte
Die Fortschritte, die wir gemacht haben, ist bisher sehr ermutigend: wir haben jetzt einen funktionierenden proof-of-concept, der zeigt den möglichen Einsatz des maschinellen Lernens in der Unterstützung zur Verwaltung von knappen Ressourcen, wie die Intensivbetten und Beatmungsgeräte. Es gibt noch Arbeit zu sein getan, aber, und viel von diesem Vertrauen weiterhin zu erhalten neue und qualitativ hochwertige Daten.
Unsere unmittelbare Priorität ist es, weiterhin zur Validierung der Modelle, die wir entwickelt haben. So tun, bringt uns näher zu finalisieren das system für die Nutzung durch medizinische Fachkräfte.
https://www.youtube.com/embed/XggvE0QOS5U?color=white
Wir müssen auch unsere Hände auf neue Arten von Daten zu machen, dass unsere bestehenden Modelle noch genauer. Insbesondere benötigen wir Längsschnittdaten, die es uns ermöglicht, ein tieferes Verständnis der progression der Patienten während Sie noch im Krankenhaus (eher als unregelmäßig aufgenommenen „Schnappschüsse“, die zeigen, dass der Zustand zu bestimmten Zeiten). Angesichts der Tatsache, wie wenig bekannt ist über COVID-19, diese Daten liefern wertvolle Erkenntnisse. Darüber hinaus hoffen wir auch für eine klare Daten in Bezug auf das timing und die Effekte der Ventilatoren, wenn verwendet, um Patienten zu behandeln. Diese würde lassen Sie uns sagen, zum Beispiel, wie lange die einzelnen Patienten könnte oder sollte, wartete vor der Lüftung zur Erzielung der bestmöglichen Ergebnisse.
Wir werden auch die Zusammenarbeit mit dem NHS (National Health Service und die Öffentliche Gesundheit in England zu verwandeln, unsere Werkzeuge in ein system, das sehr einfach genutzt werden kann und verstanden werden, die von Angehörigen der Gesundheitsberufe. In diesem Sinne, die Interpretierbarkeit ist der Schlüssel: wir wollen sicherstellen, dass die Entscheidungsträger können Debuggen und zu analysieren, die Informationen generiert unser system.


