
Machine-learning-Modell hilft CDC Vorhersagen, die Ausbreitung von COVID-19
Eine Maschine-learning-Modell, entwickelt an der UCLA Samueli School of Engineering unterstützt die Centers for Disease Control and Prevention, Vorhersage der Ausbreitung von COVID-19.
Das Modell wurde durch ein team unter der Leitung von Quanquan Gu, ein UCLA-Assistenzprofessor für informatik, und es ist nun eines von 13 Modellen, die Feeds in eine COVID-19 Prognose-Hub an der University of Massachusetts Amherst. Daten, die Nabe, die wiederum speist in der CDC, online-Prognosen für, wie könnte die Krankheit weiter zu verbreiten.
Gu sagte, sein Modell ist genauer als die meisten anderen, weil es sich nicht nur auf bestätigt COVID-19 Fällen und Todesfällen. Es ist Epidemiologie-angetrieben und ist eines von nur zwei Modellen in der Nabe, Einsatz des maschinellen Lernens.
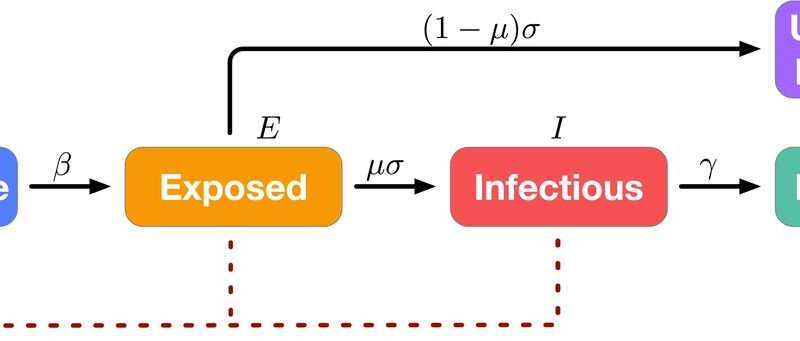
Das Modell ist der name, der UCLA-SuEIR, ist abgeleitet von den fünf Arten beobachtet und gefolgert COVID-19 Daten, Faktor, der sich in seinen Prognosen—die Zahl der Fälle kategorisiert als anfällig, nicht gemeldete, ausgesetzt, infektiöse und erholt.
Das UCLA-Modell ist einzigartig, weil es nicht einfach entsprechend der aktuellen Kurve, die ist nur auf der Grundlage von gemeldeten Fällen. Vielmehr lässt sich die Anzahl der ungeprüften und nicht gemeldeten Fällen aus der Modell-Daten-Analyse und Verwendungen, von denen Rückschlüsse Vorhersagen, wie schnell sich die Krankheit ausbreiten wird. Dies nennt man eine „Epidemie-Modell“, weil es berücksichtigt die verschiedenen Faktoren, die beeinflussen die rate der Verbreitung der Krankheit.
UCLA-SuEIR produziert state – und county-Ebene-Modelle, basierend auf den zahlen der getöteten und bestätigte Fälle gemeldet, von der New York Timesund nationale Modelle, die auf Daten basieren, berichtet von der Johns-Hopkins-Universität.
Die Universität von Massachusetts Hinzugefügt UCLA ‚ s Modell zu seiner Nabe auf 6. Mai nach Gu gesendet details über seine Arbeit zu UMass Biostatistik-professor Nicolas Reich, das hub-Projekt führen. Gu hatte das team bemerkt, dass mehrere Modelle in die Nabe waren die Herstellung unterschiedlicher Vorhersagen, meistens basiert auf der curve-fitting-Modelle.
„Ohne irgendeine Epidemie Modellierung der Projektion durch die curve-fitting-Modell ist sehr irreführend, da hängt es nur von den beobachteten Daten Muster, aber ignoriert die zugrunde liegende Epidemie Dynamik, die in den Daten“, Gu sagte.
Die UCLA-team prüft Ihre Modell-Genauigkeit, indem Sie eine Vorhersage eine Woche im Voraus in der Zukunft bestätigten Fällen, Tod und erholte Fällen, dann überprüfen Sie es gegen den tatsächlich gemeldeten Daten. Das Modell der machine-learning-Algorithmus ermöglicht eine Gu zu trainieren, einen neuen Prototyp in weniger als fünf Sekunden und ermöglicht das team zu aktualisieren sein Modell auf einer täglichen basis, die ist effizienter als die anderen Modelle. Gu hat das team eigentlich insgesamt 232 sub-Modellen im all—einen, für die USA insgesamt, sowie eine für jeden Bundesstaat und 181 für alle Landkreise mit mehr als 1.000 bestätigte Fälle.
Gu sagte, das UCLA-Modell wurde konsequent auf das Genaueste in der Massachusetts-hub in der Vorhersage von Tod zählt für die USA und die meisten Staaten, und dass es unter den top-drei Modelle, die am besten passen Ihre Prognosen mit der tatsächlichen Anzahl der Todesfälle Bundesweit.
Die Arbeit ist viel mehr als eine mathematische übung. „Unser Modell kann helfen, die Effektivität der Regierungspolitik, wie soziale Distanz, stay-at-home Bestellungen, die die Verwendung von Gesichtsmasken und deckt, oder selbst-Quarantäne, sowie die Vorhersage möglich resurges in Fällen, die Staaten wieder zu öffnen,“ Gu sagte.
Das Modell könnte auch verwendet werden, um zu bewerten, ob eine region ist Prüfung genug Leute, die helfen können, einen Beamten zu verstehen, ob weitere Tests erforderlich.
Nach dem team-Projektionen, die Anzahl der COVID-19 Fällen wird peak 1. Juni für die USA insgesamt, während Kalifornien erreicht seinen Höhepunkt am 1. Juli, und Los Angeles Fällen wird peak 7. Juni.


